Forum Replies Created
-
AuthorPosts
-
It seems that you need to add
-std=c++11as a compile-time option in environments other than Ubuntu 18.04 or later. This is because the source code was written based on the C++11 specification.@paul: The upload failed due to a problem with the file permission. Thank you for contacting me.
———-
For those who visited later …This post was corrected on 27th June 2019.
Since an error was found in the attached file, uploading is done again.
Please downloadwios-check2.zip.-
This reply was modified 7 years ago by
Masayuki Takigahira.
-
This reply was modified 7 years ago by
Attachments:
Thank you for your inquiry.
wios uses ALSA directly.
First, make sure you can record and playback using
arecordoraplay. If you set the number of bits or encoding that the hardware does not support, it may not work properly. In other words, be aware of the default settings that is used by wios.
Secondly, wios implements only some of the features of ALSA, so some devices may not be supported. For example, when recording 24-bit PCM with the--encoding 24option,S24_LEis supported butS24_3LEis not.I created a tool that I attached in this post, which can be used do a quick check. But since it has not been tested thoroughly, there may be some problems remaining. But if it works well, the output result may be helpful.
How to compile:
g++ wios-check.cpp -lasound -o wios-checkHow to use:
./wios-check <device> <type>
<type>is one ofplayback,captureorboth.
defaults:<device>ishw:0,0selected, and<type>isbothselected.
e.g.)./wios-check plughw:0,0 playbackFinally, HARKTOOL5 offers a new way to create transfer functions from TSP recordings that have not been synchronized. The information is written below, so I hope you find it useful.
[HARKTOOL5-GUI documentation] => [Transfer Function Estimation Using Complex Regression Model]
Best regards,
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
By Sylvia, did you mean you are using Linux Mint 18.3 with Ubuntu Xenial as the package base?
Although Linux Mint was derived from Ubuntu, we do not support distribution for such, So if you are using Sylvia via apt repository for the Ubuntu Xenial, I can advice you to please register again the apt repository by changing the part of$(lsb_release -cs)included in the following command toxenial.sudo bash -c 'echo -e "deb http://archive.hark.jp/harkrepos $(lsb_release -cs) non-free\ndeb-src http://archive.hark.jp/harkrepos $(lsb_release -cs) non-free" > /etc/apt/sources.list.d/hark.list'Previously registered URL (domain) of the apt repository will not be able to connect due to our server migration which may have been causing the error.
Installation Instruction for LinuxBest regards,
-
This reply was modified 7 years ago by
お問い合わせありがとうございます。
> 逆の処理も可能でしょうか。
はい。可能です。Python内で定義された変数(または定数)を
self.outputValues["端子名"]に代入して頂ければ出力されます。ネットワークファイル側では、PyCodeExecutor3ノードを右クリックし、Add Outputを選び、self.outputValues["端子名"]で指定した端子名で出力端子を追加してください。
入力はself.端子名で取得できますが、こちらもネットワークファイルのPyCodeExecutor3ノードにAdd Inputで追加した入力端子名となります。
calculate()メソッドが毎フレーム呼び出されますのでinputに対して処理してoutputするという用途が基本になります。inputが1つも無い例として、処理を開始する最初のノード(AudioStreamFromWaveのようにファイル入力等を行う)として作成する場合は、EOFでHARKの処理を停止するためにCONDITIONというbool型の出力を追加し、通常はTrue、EOFでFalseを設定します。ネットワークファイルではCONDITION端子にCONDITIONを設定してください。PyCodeExecutor3の仕様について:
HARKがサポートしている型であれば、入出力ともに可能です。例えばHARKのVectorはPythonのlistと、HARKのMapはPythonのdictと対応します。注意点としては、2点ほどあります。出力する場合はデータを渡す相手ノードの入力と型が一致している必要があります。また、HARKの標準ノードと異なりパラメータ設定ダイアログを表示できませんので、パラメータを変更できるノードを作りたい場合にはjsonファイル等でパラメータ設定が起動時にロード出来るようにする等で対応をお願い致します。Pythonコード内でsocketなど用いて記述して頂ければネットワークから動的に値を設定するコードなども可能です。Pythonコード上での処理は自由に行う事が出来ますが、HARK側からPythonのクラスを呼び出すためGUI処理(Plot等)の書き方はやや癖があります。下記ディレクトリにPlot系ノードのサンプルがありますので参考にしていただければ幸いです。
/usr/share/hark/hark-python3/harkpython/src/hark-pythonはPython2をサポートするための旧パッケージになります。HARK2.5までサポートしていました。HARK2.5以降はhark-python3としてPython3をサポートする新しいパッケージを提供しています。ユーザが記述するPythonコードについては基本的に互換性がある設計ですが、Forumの回答ではインストール手順などで旧バージョン向けの説明が書かれている事が御座います。以上、よろしくお願い致します。
お問い合わせありがとうございます。
SourceSelectorByDirectionノード(*1)の位置の件ですが、対象の音源方向が-50~50度の場合、下記の図のように接続してください。このように接続しますと、GHDSSにはノイズ音源方向を含むSource情報が、SaveWavPCMへはノイズ音源方向を除いたSource情報が渡ります。また、SaveWavPCMノードに初期状態でSOURCES端子はありませんので、右クリックからAdd InputでSOURCESという名称で追加して頂く必要があります。
*1)前回、SourceByDirectionノードと誤記していました。すみません。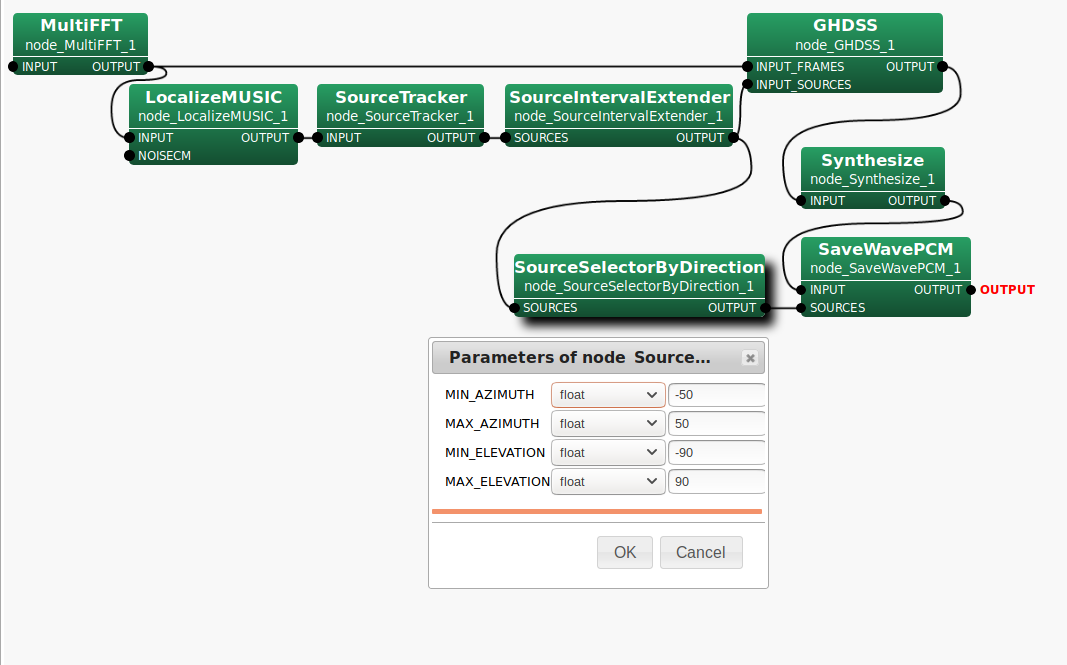
> これは、Kinect v2のマイクの問題なのでしょうか。
現在、手元にKinect v2が無いため(現行バージョンのサポートハードウェアから外れたので)実機確認が取れない状況です。申し訳ありませんがご了承ください。(定位範囲の指定で機能的な不具合が無いかは現在サポートしているTAMAGO等で確認させて頂きます。修正があった場合はChangeLogに掲載されます。)2019/06/05追記:HARK3.0.4にてLocalizeMUSICノードの定位範囲指定機能について確認致しましたので結果をご報告させて頂きます。TAMAGO03マイクアレイで機能として正常に動作している事を確認致しました。
なお、LocalizeMUSICの定位範囲指定はパワー(ノイズを含む)が強くても定位しない範囲を設定する事を意味しますので、GHDSSなどの音源分離ノードで該当方向のノイズが分離出来ない事になります。LocalizeMUSICノードの定位範囲は制限せず、SourceSelectorByDirectionノードでフィルタする事をお勧めいたします。以上、宜しくお願い致します。
-
This reply was modified 7 years, 1 month ago by
-
This reply was modified 7 years, 1 month ago by
-
This reply was modified 7 years, 1 month ago by
-
This reply was modified 7 years, 1 month ago by
-
This reply was modified 7 years, 1 month ago by
-
This reply was modified 7 years, 1 month ago by
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
Attachments:
お問い合わせ、ありがとうございます。
まず、お使いのサンプルファイルに同梱されている伝達関数は旧Kinect(v1)用のものと思われます。
https://www.hark.jp/document/supported/
より、Kinect v2用の伝達関数をダウンロードして頂き、差し替えて頂ければと思います。
マイクのチャネル数が一致しているのでクラッシュはしませんがマイク配置は異なりますので
今のままでは意図通りに動作していないと思われます。—————————————-
下記は伝達関数が正しい場合、どのような動作となっているか記載しました。
伝達関数をKinect v2用のファイルに置き換えてから読んで頂けますようお願い致します。添付して頂いた画像の音声ファイルがどのような定位結果で出力されたものか
確認させて頂いても宜しいでしょうか。実行時にDisplayLocalizationノードによって定位結果がplotされていたかと思います。
この時、「0.png」の定位結果と並行で「2.png」が定位していませんでしょうか。この場合、「0.png」の音声と「2.png」のノイズが分離された事になり正常です。
SourceByDirectionノードなどを用いると音源情報をフィルタする事が可能ですので
SaveWavPCMで音声を保存する際に自分の声の分離音だけを保存する事が可能です。GHDSSノードに入力する前にノイズの音源情報をフィルタしてしまった場合、
ノイズを分離出来なくなり指向性を持たせるだけになってしまいます。
GHDSSノードに入力するSOURCEはSourceIntervalExtenderから出力しているSource、
SaveWavPCMに入力するSOURCEはSourceIntervalExtenderの出力を一度
SourceByDirectionに入力し、SourceByDirectionでフィルタした後のSourceとします。「2.png」が「0.png」と無関係のタイミングで定位する場合。
大量のノイズが定位してしまう場合、SourceTrackerノードのTHRESHを上げる事で
不要なノイズを定位しないようにする事が可能です。もし、ご不明な点がございましたら再度お問い合わせください。
その際、お使いのHARKバージョンとOS(バージョン込み)で情報を頂けると幸いです。以上、宜しくお願い致します。
お問い合わせ、ありがとうございます。
まず、マイクへの入力から分離音が得られるまでの応答速度改善が主目的のようでしたので
分離音(正確には定位区間)の前後に無音区間が入る理由から説明させて頂きます。前方の無音区間は、SourceIntervalExtenderノードのPREROLL_LENGTHパラメータの影響です。
https://www.hark.jp/document/hark-document-ja/subsec-SourceIntervalExtender.html
[ノードの詳細]の項に記載しているように、定位区間を遡って設定するための機能ですので
前方フレームのバッファからデータを得る必要があるためノードの処理は遅延します。
SourceTrackerノードで設定するTHRESHより大きなパワーが検出されたフレームから定位開始
となりますので暗騒音(環境音)が少なくTHRESHが充分に低く設定できる環境では無音となります。
初期値として500ms(50frame)を設定していますが、音声の頭が切れない範囲で小さな値を
設定して頂くことに問題は無いかと思われます。
注)音声認識エンジンによっては発話区間の前に僅かな無音区間が必要な場合があります。後方の無音区間は、SourceTrackerノードのPAUSE_LENGTHパラメータの影響です。
https://www.hark.jp/document/hark-document-ja/subsec-SourceTracker.html
PAUSE_LENGTHパラメータの説明に記載しているように、音源が失われてからも生存期間を
超えるまで定位を延長します。本機能は、発話中の句読点にあたる位置や息継ぎなどで
一時的に発生する無音区間(ショートポーズと言われる)で定位区間が分割されることを
防ぐという目的があります。
初期値として800[1/10frames]=800ms(80frames)を設定していますが、この値を小さく
設定する事で発話終了後の無音区間を減らすことが可能です。長文を読み上げた際にも、
意図しない位置で定位が分割されない範囲で減らして頂くことは問題無いと思われます。
遅延量は減りませんが、定位区間の終了が早くなる(出力するフレーム数が減る)事で
入力に対しての応答時間も改善されるものと思われます。上記の2パラメータと無関係に無音区間が頻繁に定位するような状況でしたら、
SourceTrackerノードのTHRESHパラメータが低すぎる可能性が御座います。
定位区間が希望通りに得られれば外部VADのオーバヘッドも不要となる事が期待されます。——————–
次に下記のご質問内容についてです。
> 実時間処理をしない方法はないのでしょうか。
マイク入力のようにリアルタイム入力ではなく音声ファイル(WAVファイル等)の入力のみを
想定して高速に処理出来るか否かというご質問でしたら可能です。
内部ではstream処理を行いますが、入力待ち時間無しで処理を行うため高速に処理されます。
AudioStreamFromWaveノードのUSE_WAITパラメータをfalseに設定します。
USE_WAITパラメータでtrueを設定した場合、AudioStreamFromWaveのファイル入力でも
AudioStreamFromMicの実時間動作をシミュレーションします。この機能を無効にします。——————–
定位の精度について書かれていましたが、下記についてご確認ください。
LocalizeMUSICノードのWINDOWパラメータを変更する際、PERIODパラメータも同じ値に
変更されていますでしょうか。
WINDOWが処理する単位、PERIODが処理する間隔と考えた場合に分かりやすいのですが
PERIODが50の設定のままWINDOWだけ20に設定すると検出しない区間が発生するので、
定位精度が大幅に悪化する可能性があります。
特殊な用途を除いて基本的にはWINDOW >= PERIODとなるようにご設定ください。
注)PERIODを下げるほど計算量が増えますので計算が実時間内に終わらなくなり、
かえって応答性能が悪くなる場合があります。下げすぎにはご注意ください。——————–
最後に、SourceIntervalExtenderとLocalizeMUSICの両方で遅延が起きているか否か
については、バッファによる遅延以外(計算量の差による)の可能性も考えられますが
もう一つの可能性として下記が考えられます。
LocalizeMUSICノードのWINDOW_TYPEパラメータがFUTUREになっていないでしょうか。
https://www.hark.jp/document/hark-document-ja/subsec-LocalizeMUSIC.htmlHARKはソースコードを全て公開しておりますので、お時間のある時にソースコードを
読んで頂くと具体的な挙動などを含め理解の助けになるかもしれません。以上、宜しくお願い致します。
パラメータタイプで
objectを選択した場合に入力可能な書式の例を挙げたthreadを立てましたのでもし宜しければご参照ください。threadの名前は下記になります。
[Infomation] About the format when object is selected in parameter type以上、宜しくお願い致します。
お問い合わせありがとうございます。
添付されたネットワークファイルを確認させて頂きましたところ、
ChannelSelectorノードのパラメータが原因と判明致しました。添付されたファイルでは
<Vector <int> 1>となっていますが、
Vectorと<の間に半角スペースを含まない
<Vector<int> 1>が正しい書式となります。https://www.hark.jp/document/hark-document-ja/subsec-ChannelSelector.html
の最後に例を記載しておりますので、ご参照ください。パラメータを
objectに設定した場合の書式に関する資料が
整備されておらずご不便をお掛けしております。現在のところ
下記などから書式に関する情報が得られますのでご参照ください。- HARK-Documentのノードリファレンス
- HARK-Designer上で新規にノードを置いた際に予め入力されているデフォルト値の書式
- HARK-Designerでパラメータ入力欄にカーソルを合わせた際に表示されるtips等の記述
また、エラーメッセージ等が全く表示されない件につきましては
大変ご迷惑をお掛けしました。
今後のバージョンにて対応させて頂きたいと思います。以上、宜しくお願い致します。
2つのHarkDataStreamSenderが送信する構造体のHD_Headerに含まれるtv_secとtv_usecに入る値を比較します。片方はAudioStreamFromMicからの(該当フレームのAudio入力時の)タイムスタンプが入っており、もう一方はHarkDataStreamSenderの(該当フレームのSocket送信時の)タイムスタンプが入っております。
HarkDataStreamSenderのプロトコルについては、以前の書き込みで分離音を受信されているとの事でしたので記載しておりませんでしたが下記の仕様で送信されています。
https://www.hark.jp/document/hark-document-ja/subsec-HarkDataStreamSender.html頂いたデータ(jissoku.txt)によりますと、
4行目のtypeが0x0004、countが0x0003ですのでSRC_INFOのみ接続された左側のHarkDataStreamSenderの3フレーム目となります。
4行目のtv_sec、tv_usecにあたる場所のバイト列が59 42 a7 5c 00 00 00 00 cc b1 05 00 00 00 00 00でしたので、tv_sec=1554465369, tv_usec=373196(*1)となります。JSTになっているので+9:00されてしまっている事から、tv_secより3600*9を引く必要がありました。2行目のtypeが0x000c、countが0x0003ですのでSRC_INFOとSRC_WAVEに接続された右側のHarkDataStreamSenderの3フレーム目となります。
2行目のtv_sec、tv_usecにあたる場所のバイト列がca c3 a6 5c 00 00 00 00 53 f6 02 00 00 00 00 00でしたので、tv_sec=1554432970, tv_usec=194131(*1)となります。2行目から4行目を引くと、3フレーム目の遅延は
820,935 [us]となります。
各ノードで時間の取得方法に差がありGMTとJSTを比較する事になってしまい、ご面倒をおかけしますが宜しくお願い致します。2019/04/08 追記1:
後で読み返して説明不足と思いましたので追記させて頂きます。
*1) HARKの通信はドキュメント上で記載がない場合 リトルエンディアン で行っており、tv_secおよびtv_usecはint64_tですので 64 bits (つまり、8 Bytes)で送られています。頂いたログではpythonのprint関数でASCIIキャラクタに変換されてしまっているものがありましたので、上記では元のHEXバイト列に戻しております。2019/04/08 追記2:
おっしゃる通りWindows版でのみ問題が起きているようです。Windows版の旧バージョンに対する修正を提供する事が現状困難ですので、Ubuntu版で対応して頂けると助かります。-
This reply was modified 7 years, 2 months ago by
ほぼ同じ構成のネットワークファイルを準備し、再現試験を行っておりますが現時点では再現出来ておりません。同じバージョンのHARKを準備して確認しておりますが問題なく動作しており、HARKのバージョンによる問題ではないようです。
問題が発生した環境はUbuntuとWindowsのどちらの環境でお使いになられていますでしょうか。現在、Ubuntu環境で再現確認を行っております。再現確認を行った環境を添付させて頂きました。添付ファイルをダウンロードして頂き、次の手順を行う事で私がテストした環境と同じ構成の環境を構築する事が可能です。もし、問題が起きないようでしたらネットワークファイルの違いを比較する事で原因が判明するかもしれません。
“tcp_serve.py”のスクリプトはHarkDataStreamSenderから送信したデータを受信するためのダミーのTCPサーバで受信したデータは処理せず破棄しています。TCPサーバの終了方法は”Ctrl+C”になります。また、ネットワークファイルはTAMAGOがplughw:1,0に接続された環境で動作します。”arecord -l”を実行した際に確認できる、デバイス番号が異なる場合はAudioStreamFromMicのパラメータを変更する必要があります。(以前の書き込み内容からTAMAGOを所持されている前提で書かせて頂きました。)mkdir workspace cd workspace wget https://www.hark.jp/networks/HARK_recog_2.3.0.1_practice2.zip unzip HARK_recog_2.3.0.1_practice2.zip cd HARK_recog_2.3.0.1_practice2 cp <download_path>/time_test.tar.gz ./ tar -zxvf time_test.tar.gz python3 ./tcp_server.py tcp_server.pyを起動した後で、別のTerminal上で batchflow ./time_diff.n上記テストで問題が起きず、お使いのネットワークファイルだけ問題が起きる状況が改善できなかった場合、差し支えなければで宜しいのですが、お使いのネットワークファイル等を頂くことは可能でしょうか。再現しないためファイルを頂かなければこれ以上の解析は困難な状況です。
本フォーラムページではファイルサイズが512KB以内であれば最大4ファイルまで同時に添付する事が可能です。以上、宜しくお願い致します。
Attachments:
原因が判明いたしましたのでご連絡させて頂きます。
「4.」について
スクリーンショットで右側に配置されたHarkDataStreamSenderのSRC_INFO端子の入力ですが、SourceIntervalExtenderの出力端子から接続する必要があります。SRC_WAVE、SRC_FFT、SRC_FEATURE、SRC_RELIABILITYの各入力端子を使用する場合、SRC_INFOはそれらの計算に用いたSource情報である必要があります。
右側のHarkDataStreamSenderでSRC_WAVE端子に入力されている分離音はGHDSSでSourceIntervalExtenderのSource情報によって分離されています。そのため、SourceIntervalExtenderの出力をSRC_INFO端子へ接続する必要があります。
左側のHarkDataStreamSenderは上記に挙げた4入力(SRC_WAVE、SRC_FFT、SRC_FEATURE、SRC_RELIABILITY)を使用していませんのでSourceTrackerとSourceIntervalExtenderどちらの出力をSRC_INFOに入力しても動作します。ただし、SourceIntervalExtenderを通していないため定位区間の結果は変わります。SourceIntervalExtenderは定位区間を前方に拡張していますので、お使いのネットワークではSRC_WAVEの入力はあるがSRC_INFOの入力が無いという状態が右側のHarkDataStreamSenderで発生しています。そのため、ソケットから送信するデータ構造が作れないためエラーとなっております。
以上、ご確認のほどよろしくお願いします。
「1.」について
はい。入力された音響信号の重複部分は同じデータとなります。入力信号のシフト量とウィンドウ幅を独立で設定出来るように設計されています。「2.」について
すみません。おっしゃる通り -1 を行うのが正しいです。「3.」について
はい。どちらのノードもバッファで以前のフレームのデータを保持しており、50フレーム目を受信してから処理が開始できるという事ですのでネットワーク全体で1回だけ考慮するだけで済みます。「4.」について
ネットワークのスクリーンショットを拝見する限りでは特に問題が無く見えましたので、こちらでも再現確認をさせて頂きます。そのため、少々お時間を頂けますでしょうか。
また、エラー出力の内容からHARK2.xと思われますが、HARKのバージョンを確認させて頂いても宜しいでしょうか。「5.」について
すみません。前回、見落としていたようです。
> 前後に余裕を持った(前後に無音(に近い)が入っている)ものとなっていると思われ、
> ”発話区間”ではないと思われますがいかがでしょうか。
SourceTrackerのPAUSE_LENGTHとSourceIntervalExtenderのPREROLL_LENGTHにより前後に余裕が出ています。もし、前後の無音区間を無くしたいという事でしたらパラメータを調整して頂く必要があります。SourceTrackerのPAUSE_LENGTHについては短くしすぎると長文を発話している場合などにショートポーズ(息継ぎや句読点)の位置で定位結果が分割されることがありますのでご注意ください。
下記URLにノードの説明が御座います。音声認識が目的の場合、認識エンジンによっては(特に前半部の)無音区間が無い場合に性能(認識率)が低下する事が御座いますのでご注意ください。また、後半の無音区間については無音に見えても(例えば「センター」の「ー」の部分などの)音素や残響などが含まれているケースがありますので短く設定されたい場合はそのような点もご考慮の上でご設定ください。
https://www.hark.jp/document/hark-document-ja/subsec-SourceTracker.html
https://www.hark.jp/document/hark-document-ja/subsec-SourceIntervalExtender.html以上、宜しくお願い致します。
-
This reply was modified 7 years, 3 months ago by
-
This reply was modified 7 years, 3 months ago by
すみません。段落を付けていませんでしたので混乱させてしまいました。
イメージ画像を添付いたしましたのでご確認下さい。
2019/04/02 14:50:00 追記:
添付イメージに誤りがありましたのでframes_revised.pngとして再アップロードしました。
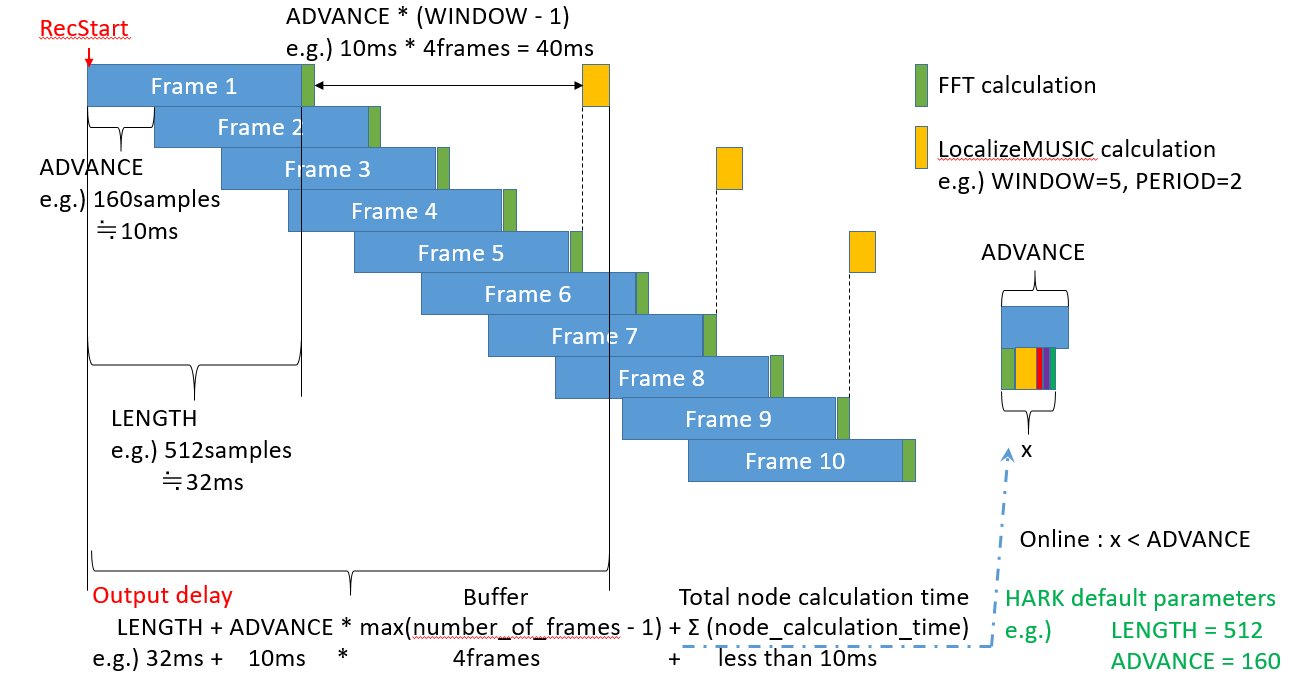
旧イメージのframes.pngは記録のために残してありますが、誤りを含んでいます。言葉で説明すると次のようになります。
1.HARKではFFTのようにWindow処理を行うノードがありますのでWindow幅でバッファする必要があります。そのため、16kHzサンプリングでWindows幅(LENGTHと呼ばれるパラメータ)に512サンプルと設定した場合、約32ms固定で入力が遅延します。これはネットワークがどのように接続されていても固定です。
2.シフト量(ADVANCEと呼ばれているパラメータ)で160サンプルと設定した場合、1frameは10msとなりますので各ノードは10ms間隔でデータを受け取ります。
3.ノードによって、複数フレームをバッファする事があります。LocalizeMUSICなどがその例です。WINDOWで50と設定すると50フレーム得られてから計算を開始します。各ノードはストリームで処理されますので、ノードの中で最も大きなフレーム数だけを考慮します。
4.各ノードでは計算時間のため遅延が発生しますが、オンライン処理が可能なものは1フレーム以内に計算を終えます。そのため、追加の遅延時間として1フレーム(10ms)分だけ考慮します。そのため、お使いのネットワークファイルでは32ms+
500400ms+10msで540440msぐらいと思われます。—-
> AudioStreamFromMicからのTIMESTAMP端子の接続方法でうまくいかないのですが、
LocalizeMUSICの項目に端子の追加方法について掲載しておりますので、
以下の方法と同じ手順でAudioStreamFromMicにTIMESTAMPという名称の出力端子を
追加してください。
https://www.hark.jp/document/hark-document-ja/subsec-LocalizeMUSIC.html> documentにはTIMESTAMPの信号情報が載っておりませんが、
すみません。AudioStreamFromMicのTIMESTAMP端子についての情報がdocumentに記載されていませんでした。今後のメンテナンスの際に追記させて頂きます。
-
This reply was modified 7 years, 3 months ago by
-
This reply was modified 7 years, 3 months ago by
Attachments:
-
This reply was modified 7 years ago by
-
AuthorPosts