
Forum Replies Created
-
AuthorPosts
-
You need to use
hark_msgs/HarkWavein your workspace.
In your case,audio_common_msgs/AudioDataseems to storemp3data intouint8[]array, so you will first need to expand it to raw PCM data.Second, the data structure of
hark_msgs/HarkWaveis as follows.user@ubuntu:~$ rosmsg show hark_msgs/HarkWave std_msgs/Header header uint32 seq time stamp string frame_id int32 count int32 nch int32 length int32 data_bytes hark_msgs/HarkWaveVal[] src float32[] wavedatawavedatais a raw PCM data array. Since HARK is not aware of the number of bits, it simply casts an integer value to a floating point type. In other words,123is123.0f.data_bytesis the data size. In other words, it is the size offloat(4 bytes) multiplied by the size ofwavedata.lengthis the number of samples per frame handled by HARK. The initial value of HARK is512. Since HARK processed frame by frame, in other words, the size ofwavedatamust benchtimeslength=512.nchis the number of channels. Your device seems to be 1ch, so it should be1. For microphone array data, a larger number will be stored.countis the frame count. Since HARK processing frame by frame, it is necessary to know what frame the data is. In other words, it is incremented as the frame advances. The first frame number is0. Not1.There is a final note. In order to prevent problems in FFT/IFFT processing, etc., the frames processing by HARK are subject to sample overlap processing.
The following image may help you understand.
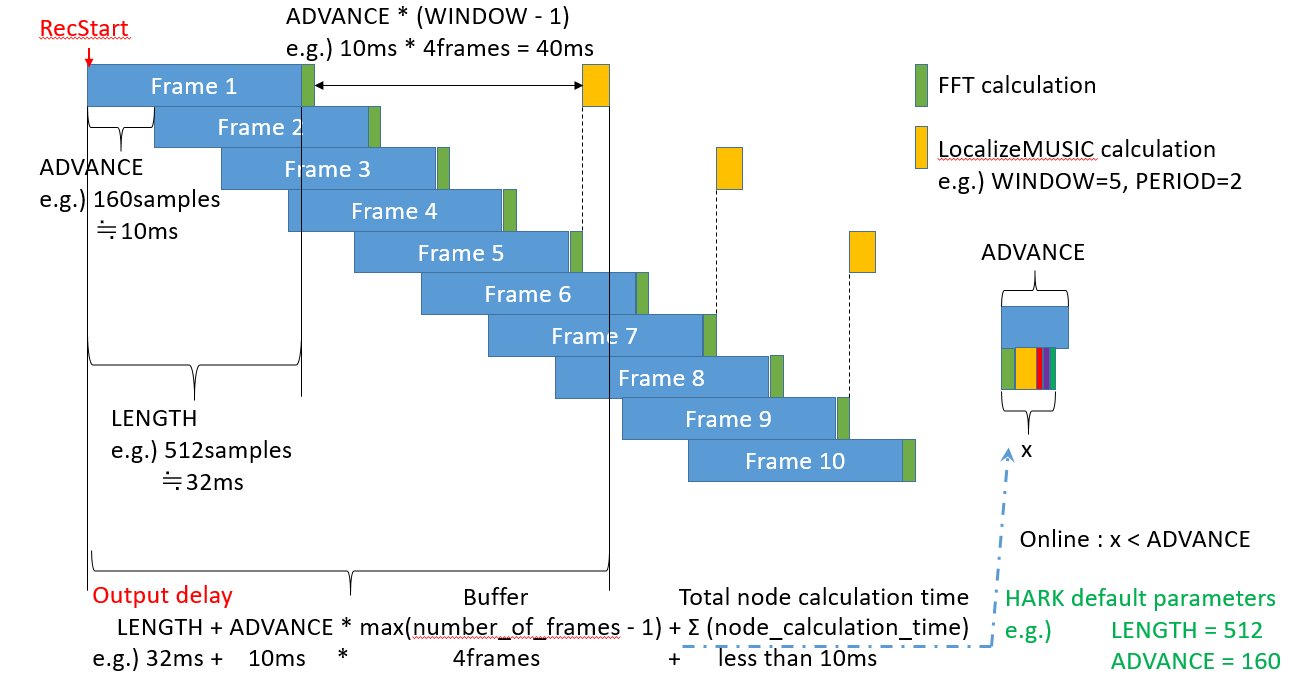
Best regards,
m.takigahiraSample code is not provided from the official website, but specifications and source code are available. I hope you find it helpful.
There is only one point to note. Since the data is transmitted in little endian, it is not in the network byte order generally called.Please refer to the next url for specifications.
https://www.hark.jp/document/hark-document-en/subsec-HarkDataStreamSender.htmlThe source code can be obtained with the following command on Ubuntu.
apt source hark-coreIn the case of Windows environment, it is probably easy to download from the following URL.
http://archive.hark.jp/harkrepos/dists/bionic/non-free/source/
You can download any version by clicking the following file name on the browser. The<version>will be in the form of “x.x.x”.
hark-core_<version>.tar.gzBest regards,
m.takigahiraThe Windows version of wios supports only the function to record via the network that RASP-24 etc. supports. In other words, wios can be used only when recording over the network with a USB-LAN or USB-Wireless dongle inserted into the USB port of the RASP-ZX.
Currently, when connecting directly with a USB cable, you can only create a WAV file with a third-party recording tool such as Audacity. HARKTOOL5 can create a transfer function with an Complex Regression Model that does not require synchronized recording.
https://www.hark.jp/document/packages/harktool5-gui-en/harktool5-gui.html#fd-conv-label
If you need a TSP wav file created by synchronized recording, the following workaround also exists.
Please create Ubuntu installed the virtual machine on VMWare/VirtualBox on Windows and connect RASP-ZX to the virtual machine. In that case, you can record with ALSA.
Best regards,
m.takigahira——————————————————————————————
Since I noticed that there was a mistake, I deleted it immediately after the following post. wios did not support both WASAPI and DirectSound (DS) at this time. Only the RASP protocol that cannot be supported by the standard Windows API is supported.
The RASP-24 is connected via a LAN, and the recording data is transmitted over the network using the SiF original protocol and recorded using the SiF original interface.The USB Audio Class (UAC) supported devices connected via USB, such as TAMAGO-03, are recorded with WASAPI or DirectSound (DS) interface.RASP-ZX supports two connection methods.
If you are connected directly to a PC with a USB cable, it will be recorded with WASAPI or DS interface. On the other hand, if a USB-LAN or USB-Wireless dongle is inserted into the USB port and you are trying to connect via a network, it will be connected with the SiF original protocol as same as RASP-24.You need to choose a wios command depending on which connection method you use.Notes:
HARK has supported WASAPI since version 3.0, but wios has not yet completed support for WASAPI, DirectSound (DS) will be used. The effect of this difference will hardly occur.Best regards,
m.takigahira-
This reply was modified 6 years, 10 months ago by
Masayuki Takigahira.
-
This reply was modified 6 years, 10 months ago by
-
This reply was modified 6 years, 10 months ago by
-
This reply was modified 6 years, 10 months ago by
July 26, 2019 at 4:17 pm in reply to: HARK音声認識セット("HARK_recog_2.3.0.1_practice2")のモデルを自作モデルに差し替えたい。 #1083> 私の環境上直近で用意できるのがnnet1モデルのみであるため、
> どうにかnnet1で動作させたいという思いがございます。
理解しました。> ご教示いただいた内容からnnet3の場合Kaldiのモデル作成からやり直す必要が
> あるように見受けられますがnnet1の場合も同様なのでしょうか。
MSLS特徴量を使用したい場合は、HARKでしかMSLS特徴量を生成できませんので再学習が必要になります。一方で広く一般的に使われるMFCC特徴量もHARKで計算する事が出来ますので、性能等に差が出る場合もございますがMFCC特徴量で学習されたモデルをKaldiDecoderで使う事は可能です。
HARKの分離音をSaveWavePCMで出力して学習に使用された場合などは、CSJの学習レシピを変更していなければKaldiがMFCC特徴量に変換して学習しているはずですので、再学習しなくても設定変更だけで済むものと思われます。その場合、お使いの環境で下記の変更が必要となります。1.HARKのネットワークファイルの差し替え
Kaldi公式レシピでPCMデータから学習している場合、KaldiDecoderには40次元のMFCC特徴量を入力する必要があります。上の投稿にありますように、入力した特徴量形式と次元数が一致していれば特徴量空間での適応処理(fMLLR)を行って作成されたモデルの場合でも問題なくデコードできます。
HARK_recog_2.3.0.1_practice2 に含まれるネットワークファイルでは特徴量の次元数が異なりますので修正が必要です。40次元の特徴量を作るHARKのネットワークファイルのサンプルは、 HARK_recog_3.0.0_practice2.zip に含まれております。注意点として、 MSLSExtraction ノードでMSLS特徴量を生成している部分を MFCCExtraction ノードに置き換えて頂く必要が御座います。MFCCExtractionノードのパラメータは MSLSExtraction と同じように40次元となるように設定して差し替えてください。2.KaldiDecoderに渡すconfigファイルの変更
上の投稿にありますように、KaldiDecoderに読み込ませるconfファイルへ下記の行を追記してください。
--splice=17以上、宜しくお願い致します。
July 25, 2019 at 12:12 pm in reply to: HARK音声認識セット("HARK_recog_2.3.0.1_practice2")のモデルを自作モデルに差し替えたい。 #1077お問い合わせありがとうございます。
ご質問の目的ですが、CSJコーパスで学習された音響/言語モデルが必要という認識で宜しいでしょうか。
nnet3形式のchain modelで宜しければ、学習済みのモデルが下記ページよりダウンロード可能です。
https://www.hark.jp/download/samples/現行の最新版(HARK3.0)のサンプルファイルがCSJで学習されたモデルとなります。
次のファイルをダウンロードして頂けますでしょうか。
HARK_recog_3.0.0_practice2.zip従来のnnet1形式のモデルに比べ認識性能、処理速度なども向上しておりますので、
今後も互換性のためにnnet1形式のモデルを使用して動作させる事は可能ですが
理由が特になければnnet3形式のモデルへ移行される事を推奨しております。モデルの変更にあたり、デコード時に使用する特徴量は
特徴量13次元 + Delta特徴量13次元 + DeltaPower特徴量 の27次元から
特徴量40次元 に変更となっています。ご了承ください。—-
また、将来的にご自身で学習されたモデルへ入れ替えたいという事でしたら、
HARK Forum内の下記スレッドでKaldi公式の学習レシピ(nnet3用)から変更が
必要な点についての回答が行われていますので宜しければご確認ください。
音響モデルの作成についてまず、GMMの学習に13次元のMSLS特徴量、chain学習に40次元のMSLS特徴量が必要となります。
SpeechRecgnitionClientのFEATURESへの入力をSaveHTKFeatureに繋ぎ変える事でHTK形式の特徴量ファイルが出力されます。
デコード時(音声認識セットのサンプル)は40次元の特徴量のみをSpeechRecgnitionClientにて送信していますが、学習の為には別途13次元の特徴量が必要になりますのでご注意ください。
上記のスレッドを参考にHARKで出力したHTK特徴量をKaldiのark形式に変換して頂いた上で、Kaldiへ入力して学習してください。
我々が提供しているモデルではiVectorに100次元を使用しております。
他の設定は HARK_recog_3.0.0_practice2.zip の kaldi_conf ディレクトリをご参照ください。Notes:
Kaldi公式のレシピでPCMデータから直接作成してしまいますと、
MSLS特徴量には対応していませんのでMFCC特徴量が使われます。
MSLSExtractionの代わりにMFCCExtractionというノードを使用する事も可能ですが、
この場合も特徴量の次元数等の設定については学習時と合わせて頂く必要が御座います。以上、宜しくお願い致します。
-
This reply was modified 6 years, 11 months ago by
If the new question is related to this post, please post in the same thread. Conversely, if the new question is not relevant, please post in a new thread with the appropriate subject. It will probably help people with the same problem to find a solution.
I and we (HARK support team) hope this forum will help you.
Best regards,
-
This reply was modified 7 years ago by
Thank you for your inquiry.
Please check the following points.
Case.1:
Separate human voices with HARK. In other words, if the sampling rate is sufficient at 16kHz, then:1. Although the TSP response file is recorded at 48 kHz, please downsample this file to 16 kHz. Because
16384.little_endian.wavis a TSP file for the 0 to 8 kHz.
2. HARKTOOL creates a transfer function from the TSP response file for the 0 to 8 kHz. In other words, it is not necessary to change the paramter settings for the number of samples by HARKTOOL.
3. In the HARK network file, connect the MultiDownSampler node after the AudioStreamFromMic node, and downsample from 48kHz to 16kHz. And, the LocalizeMUSIC and GHDSS nodes use a transfer function for the 0 to 8 kHz.Normally, 16 kHz is sufficient to process the human voice band.
Case.2:
If you need to separate up to very high frequency bands like electronic sounds. In that case, do not use 16384.little_endian.wav. You need to recreate the TSP file itself for 48kHz. In other words, it is a TSP file up to 24kHz, which is the Nyquist frequency.In this case, the 786,432 samples that you wrote in the post are correct as calculations.
If you can read Matlab script, my script may be helpful. In my code, TSP file and inverse TSP file are generated by specifying sampling rate etc. The reason for duplicating the channel of TSP file is to ensure that wios does not fail if the playback device is stereo.
I think my script maybe works with Matlab’s Clone (eg octave) too, but I will attach a 48kHz sample just in case.
Best regards,
Attachments:
I’m sorry, I noticed that there was an error in the command I posted before.
I apologize for the confusion caused by the wrong information.Please try the following command:
In this example, plughw:1,0 is a recording device and plughw:0,0 is a playback device.wios -s -y 0 -d plughw:0,0 -z 0 -a plughw:1,0 -c 8 -i input.wav -o output.wavThe meaning of
-y 0is that the playback device is an ALSA device.
The meaning of-d plughw:0,0is that the playback device isplughw:0,0.
The meaning of-z 0is that the recording device is an ALSA device.
The meaning of-a plughw:1,0is that the recording device isplughw:1,0.
-yoption and-zoption are used instead of-xoption.
Because the recording and playback devices are different (there are two), you need-yand-z. If you can record and play back on one device, eg RASP, use only-x.Best regards,
-
This reply was modified 7 years ago by
お問い合わせありがとうございます。
> hark-base
> harkmw
> libharkio3
> libhark-netapi
> hark-core
> harktool5現在、公式がサポートしているアーキテクチャはIntel系のx86_64のみ(*1)ですので
上記は全てソースコードからビルドされているという認識で宜しいでしょうか?
*1) FAQ: What are the supported architectures by HARK?ARM系プロセッサでは
CFLAGSやCXXFLAGS等で指定する最適化オプションで
性能が大きく変わる事が御座います。未設定の場合はご検討ください。以降、CPUに合わせたコンパイラオプションが適切に設定されているという前提で
書かせて頂きます。.bashrc等で下記の環境変数を追記してから試して頂けますでしょうか。
.bashrcに書いた場合、端末(bash)を立ち上げなおすと反映されます。
HARK-Designer上から実行する場合は、hark_designerコマンドを起動する
端末を立ち上げなおしてHARK-Designer自体も再度起動してください。export OPENBLAS_NUM_THREADS=1もし、他にもOpenBLASを使用しているアプリケーションがあり
環境変数の設定を全体(全てのbash)に反映したくないというケースでは
HARKを実行する際に、下記のように実行する事でコマンドのみに反映されます。
この方法の場合、HARK-Designer上から実行すると反映されません。
必ずコマンドラインからHARKを実行して頂く必要が御座います。OPENBLAS_NUM_THREADS=1 harkmw ./<your_network_file>.nHARK3.0より、実行コマンドの名称が
harkmwに変更されましたが
harkmwの部分は従来通りbatchflowと書いても実行できます。
互換性の為にエイリアスとして設定されているので機能は同じです。以上、宜しくお願い致します。
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
First of all, I will talk from factors other than parameters.
Case.1:
If the overall system speed is slowing, the following causes may be considered. If you execute thread processing in a small matrix whose element size is less than a few thousand, calculation units are excessively divided, and the overhead reduces the speed of the OPENBLAS library.Therefore if you are using HARK 3.x, try setting the environment variable
OPENBLAS_NUM_THREADS=1.For example, set the following line in the
.bashrcfile:export OPENBLAS_NUM_THREADS=1In this case, variables will be effective from the newly opened terminal.
Or you can do the following when you run the network file:
OPENBLAS_NUM_THREADS=1 harkmw ./your_networkfile.nIn this case, variables apply only to the command.
Case.2:
If only the processing speed of HARK is decreasing, the following causes may be considered. Please check the following contents.- Make sure that the known sound signal input to the HarkMsgsStreamFromRos node is not intermittent. For example, if a robot performs TTS, the sound signal must be transmitted not only during speech but also during silence periods.
- Make sure that the sampling rate of the microphone array input matches the sampling rate of the sound signal input to the HarkMsgsStreamFromRos node. If it is difficult to match, please adjust the input of HarkMsgsStreamFromRos node to the sampling rate of the microphone array by MultiDownSampler node. Note that if you lower the sampling rate on the microphone array by MultiDownSampler node, you need to recreate the transfer function.
Case.3:
If the parameters of SemiBlindICA node seems to be the cause, please check the following contents.- Please check the background noise level contained in the microphone array input. The SemiBlindICA node’s IS_ZERO parameter is used to determine input levels of INPUT that do not need to be processed, since it is not necessary to perform estimation processing during periods where there is no sound signal input (silence period) of REFERENCE. Note that this parameter should be set with power in the frequency domain.
- Please save the output of AudioStreamFromMic node and HarkMsgsStreamFromRos node with SaveWavePCM. If you compare the sound signals recorded in the two WAV files, you should see something like this:
The waveform of the audio signal obtained at the HarkMsgsStreamFromRos node should be recorded at the AudioStreamFromMic node with a slight delay. The larger the delay amount, the larger the value of the TAP parameter, but if it is excessively large, the amount of calculation increases. However, if it is slow enough to misunderstand it as a hangup, I think that it is not the influence by this parameter.
Best regards,
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
Thank you for your inquiry.
I have confirmed your screen shot. The main cause is that the HarkMsgsStreamFromRos node is placed on the MAIN sheet. Please move the HarkMsgsStreamFromRos node to the MAIN_LOOP sheet and connect MATOUT terminal to the MultiFFT node (The side connected to REFERENCE) on the same sheet. It takes iterations to perform frame-by-frame calculations.
Best regards,
Thank you for reporting this error.
And, I appreciate your help confirming the operation of the debug version.It has been confirmed that this error is caused by compiler optimization. Currently, we are preparing a package for publishing with a reduced optimization level as a workaround. It will be released in the next few days.
The version with the bug fixed will be “WIOS 3.0.7.1”. Please wait for it to be posted on “News” page.
Best regards,
-
This reply was modified 7 years ago by
I prepared three TSP files recorded at different locations with different microphone arrays. The figure below shows an excerpt of one channel, which you open in Audacity to see the spectrogram.
In the two examples below you will see frequency components other than the original TSP signal. This is due to harmonics or reflected waves. It would be desirable to set the largest volume without such extra information.
The following three examples are TSP files that function without any problems in performance. In other words, it is the limit value of the volume that harmonics and reflected waves are barely visible as shown below. Be careful not to make the line due to harmonics or reflected waves more strongly than that. It is most desirable to adjust to the invisible state as in the example at the top.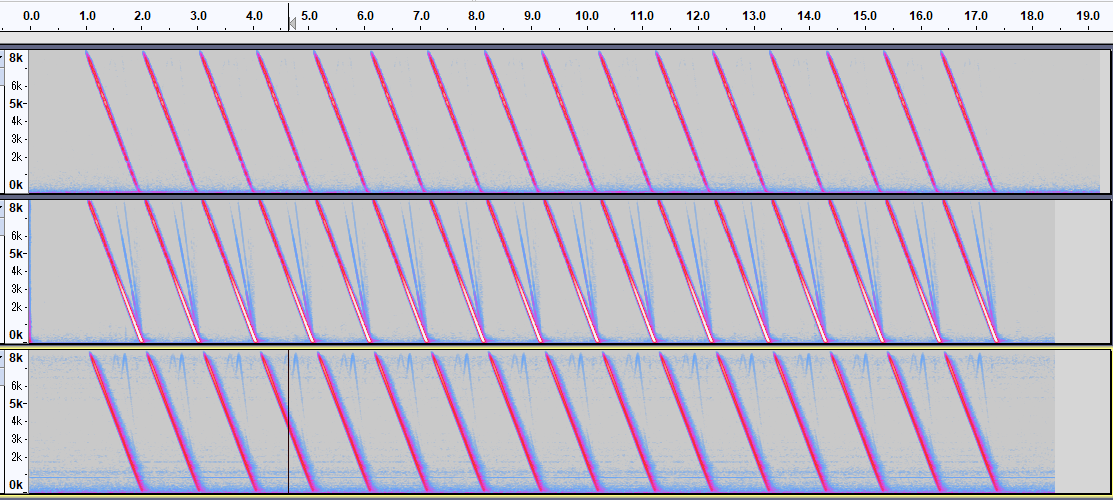
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
Attachments:
お問い合わせありがとうございます。
DisplayLocalizationノード等へ入力されていますので、PyCodeExecutor3ノードの出力はVector<Source>型になっていなければなりません。全てのノードについて入出力の型が掲載されていますので、詳細はHARK-Documentのノードリファレンスをご参照ください。つまり、今回のケースは出力端子の型設定を
self.outputTypes=("prime_source",)
ではなく
self.outputTypes=("vector_source",)
と設定する必要が御座います。それに伴い
self.outputValues["output"] = self.input[0]
と書かれている行についても次のようにする必要が御座います。
self.outputValues["output"] = [self.input[0]]
更に、入力されたVectorサイズが0である(定位無しの)可能性が御座いますので、次のようにしていなければ実行中にクラッシュする可能性が御座います。
self.outputValues["output"] = [] if len(self.input)<1 else [self.input[0]]また、余談ですが
self.outputValues["output"] = self.input self.outputValues["output"] = self.input[0]のように同一出力端子に2度書き込みを行った場合、
後で書き込まれた値のみが使われます。
calculate()メソッドを抜ける時点で設定した型と
最終的に書き込まれている型が不一致している場合には
エラーが発生しますのでご注意ください。以上、よろしくお願い致します。
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
> Unfortunately, it did not give me any new information on how to overcome my problem with wios (see results of my wios_check in attachments).
@paul: No. I saw your results and understood at least one of the causes.You can use following channels argument with the wios command. -c <channels> (same as --channels <channels>) *) Please select one of ( 2 ) as <channels>.This means that your device only supports 2 channels. If your device supports 1 or 2 channels, you will see the following message:
You can use following channels argument with the wios command. -c <channels> (same as --channels <channels>) *) Please select one of ( 1-2 ) as <channels>.Also, while wios defaults to 16 kHz for the sampling rate, your device does not support 16 kHz. Your device supports only the sampling rates below. In other words, 44.1 kHz, 48 kHz, etc. should be selected.
your playback device:
You can use following sampling rate argument with the wios command. -f <rate> (same as --frequency <rate>) *) Please select one of ( 44100 48000 96000 192000 ) as <rate>.your capture device:
You can use following sampling rate argument with the wios command. -f <rate> (same as --frequency <rate>) *) Please select one of ( 44100 48000 96000 ) as <rate>.——
You will need to do some things:
– The tsp1.wav that you used is 1 Channel (Mono) data, but you need to make it 2 Chennels (Stereo).
e.g.) If you use a tool calledsox, the following will duplicate the channel after rate conversion:
sox tsp1.wav -r 48000 tsp2.wav remix 1 1
Instead, please try using the output tsp2.wav.
– Please set the channel number explicitly as-c 2on your device. It is not-c 1.
– Please set the sampling rate explicitly as (e.g.)-f 48000on your device. It is not-f 16000(This is the wios default if not set).——
The following commands should work on your device.
arecord -d 16 -D plughw:0,0 -f S32_LE -c 2 -r 48000 output.wav
To make it work the same way:
wios -r -x 0 -t 16 -a plughw:0,0 -e 32 -c 2 -f 48000 -o output.wavThe following commands should work on your device.
aplay -D plughw:0,0 tsp.wav
To make it work the same way:
wios -p -x 0 -d plughw:0,0 -i tsp.wav
*) tsp.wav must be 48 kHz, 32-bit (or 16-bit) 2-channel data.The settings for syncing your recording and playback devices in this example are:
wios -s -x 0 -y plughw:0,0 -z plughw:0,0 -e 32 -c 2 -f 48000 -i tsp.wav -o output.wav
wios -s -y 0 -d plughw:0,0 -z 0 -a plughw:0,0 -e 32 -c 2 -f 48000 -i tsp.wav -o output.wavNotes:
If you get an error message about buffers (for example, buffer overruns), you can work around by setting the buffer size larger than the initial value using the-Nand-Zoptions.I hope this answer will help you solve your problem.
Best regards,
-
This reply was modified 7 years ago by
-
This reply was modified 7 years ago by
-
This reply was modified 6 years, 10 months ago by
-
AuthorPosts