Forum Replies Created
-
AuthorPosts
-
Thanks for the fast reply. Right now I am only interested in localization. I believe that even before you use the MultiFFT node in a standard localization network there has to be some sort of low-pass filtering. Otherwise the real-time spectrum coming out of the MultiFFT node is corrupted by aliasing.
Paul
EDIT: I just realized my mistake. Of course the relatively small sampling frequency of 16 kHz will always introduce a small amount of aliasing into the signal. It makes absolutely no sense asking for a filter AFTER the audio has been recorded.
-
This reply was modified 6 years, 8 months ago by
paul.
Thank you, I successfully created a TF with wios.
Paul
Im glad I could help. However I experienced a new problem with the debug version when using synchronous mode and an external recorder (plughw:1,0):
wios -s -x 0 -z plughw:1,0 -i input.wav -o output.wav (=>Fail)
If I enter the command above it only shows me the wios help page. As if I typed “wios -h”. It feels like it doesnt even know the option “-z”. Synchronous mode only works when leaving out “-z plughw:1,0” and therefore using the default setting. Although if I explicitly type in “-z plughw:0,0” it again shows me the help page ¯\_(ツ)_/¯
“plughw:1,0” works fine in recording mode:
wios -r -x 0 -t 4 -o output.wav -a plughw:1,0 -c 8 (=>Success)-
This reply was modified 7 years ago by
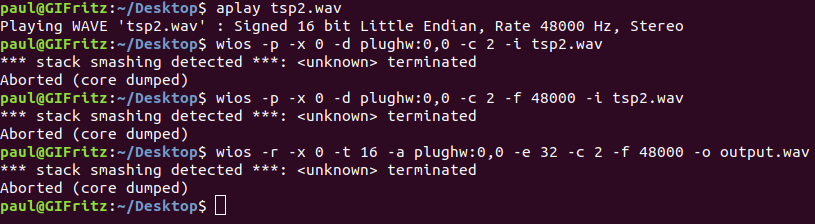
@Masayuki Takigahira: I understood the wios_check_results and already tried -c 2 and -f 48000 together. What I did not think of was making the tsp a 48kHz stereo sound before playback with wios. Sadly, the results are the same (see attachment).
Attachments:
@Masayuki Takigahira: Thank you. The script compiled successfully. Unfortunately, it did not give me any new information on how to overcome my problem with wios (see results of my wios_check in attachments). I hope I can do without wios.
Paul
Attachments:
@Masayuki Takigahira: Thank you for your detailed reply and writing an extra tool. I would love to try out the tool because arecord and aplay work just fine and I still dont understand why wios is not working. I dont see any attachments to your post though 🙁
@Rohan: I wrote a very simple bash-script which records an plays almost simultaneously using arecord and aplay (see end of post). Maybe measure the unavoidable latency between both arecord and aplay commands in a practical experiment were you put speaker and microphone right next to each other. With that information you can maybe later edit the tsp responces accordingly. I will put it to a test soon if I cant get wios working.
!/bin/sh
echo “Starting…” 1>&2
arecord -d 2 -D plughw:1,0 -f S32_LE -r 48000 roomname_distance_d$1.wav &
aplay tsp.wav -
This reply was modified 6 years, 8 months ago by
-
AuthorPosts